-
TIL_200611Today I Learned 2020. 6. 12. 00:30
데이터베이스(Database)
데이터를 어디에 저장할 수 있을까요?
만약에 클라이언트에 저장한다면(In-memory) 사용자가 클라이언트를 종료할때 데이터 또한 사라집니다.
그렇다면 클라이언트에서 통신하고 있는 서버에 저장(File I/O)한다면 어떨까요? 서버에 데이터를 저장한다면 클라이언트가 종료되어도 서버에 남아있지만 특정 데이터를 가져오고 싶다면 전체 데이터를 클라이언트에서 받아서 가공하여 원하는 부분을 추출해야하는 번거로움이 있습니다. 데이터를 어딘가에 분류하여 저장해 놓고 원하는 부분만 꺼내올 수 있다면 편할 것입니다. 이를 위해서 데이터 베이스(Database)에서 만듭니다.
데이터 베이스에 엑세스하고 조작하기 위한 표준언어인 SQL을 사용합니다.
SQL(Structured Query Language)로 할 수 있는 것
- 쿼리를 실행
- 데이터를 검색
- 레코드를 삽입
- 레코드를 업데이트
- 레코드를 삭제
- 새로운 DB생성
- 새로운 테이블 생성
- 저장 프로 시저 생성
- 뷰를 생성
- 테이블, 프로 시저 및 뷰에 대한 권한을 설정
SQL은 ANSI/ISO표준이지만 다른 버전의 SQL 언어가 있습니다. 그러나 ANSI표준을 준수하기 위해 최소한의 주요 명령을 유사한 방식으로 지원합니다.
RDBMS(Relational Database Management System)는 관계형 데이터베이스 관리 시스템입니다.
모든 최신 데이터베이스 시스템의 기초입니다.
RDBMS의 데이터는 테이블이라는 데이터베이스 객체에 저장됩니다. 테이블은 관련 데이터 항목의 모음이며 열과 행으로 구성됩니다.
모든 테이블은 필드라고 하는 더 작은 엔티티(entity)로 나뉩니다.
필드는 테이블의 모든 레코드에 대한 특정 정보를 유지하도록 설계된 테이블의 열입니다.
행이라고도 하는 레코드는 테이블에 존재하는 각 개별 항목입니다.
열은 테이블의 특정 필드와 관련된 모든 정보를 포함하는 테이블의 수직 엔티티입니다.
데이터베이스 테이블 (Database Tables)
데이터베이스는 하나 이상의 테이블로 구성되어 있습니다. 각각의 테이블은 이름으로 구별됩니다.
테이블에는 행(row)으로 데이터가 있는 레코드가 포함됩니다.
아래의 표에는 2개의 레코드와 7개의 열로 구성되어 있습니다.
CustomerID CustomerName ContactName Address City PostalCode Country 1 Alfreds Futterkiste Maria Anders Obere Str. 57 Berlin 12209 Germany 2 Ana Trujillo Emparedados y helados Ana Trujillo Avda. de la Constitución 2222 México D.F. 05021 Mexico SQL 키워드는 대소문자를 구분하지 않습니다. select는 SELECT와 동일합니다.
SQL 문 이후에는 세미콜론이 필요합니다.
중요한 SQL 명령들
- SELECT- 데이터베이스에서 데이터를 추출
- 업데이트 -데이터베이스의 데이터를 업데이트
- DELETE- 데이터베이스에서 데이터를 삭제
- INSERT INTO- 데이터베이스에 새 데이터를 삽입
- CREATE DATABASE- 새 데이터베이스를 생성
- ALTER DATABASE- 데이터베이스 수정
- CREATE TABLE- 새 테이블을 생성
- ALTER TABLE- 테이블 수정
- DROP TABLE- 테이블을 삭제
- 색인 만들기 - 색인을 생성 (검색 키).
- DROP INDEX- 색인을 삭제
SELECT
데이터베이스에서 데이터를 선택하는 데 사용됩니다. 선택한 데이터는 반환되며 result-set이라는 result table에 저장됩니다.
SELECT colnum1, colnum2, ... FROM table_name;SELECT customerName, city FROM customers;( * )은 해당 테이블의 모든 열을 선택합니다.
SELECT * FROM customers;SELECT DISTINCT
테이블의 열에 어떤 하나의 값이 중복되어있다면 distinct로 중복되지 않는 하나의 값을 보여줍니다.
SELECT DISTINCT country FROM customers;COUNT는 해당 열의 수를 보여줍니다.
SELECT COUNT(DISTINCT country) FROM customers;WHERE
레코드를 필터링하여 지정된 조건을 충족하는 레코드만 추출합니다. (UPDATE와 DELETE에도 사용됩니다.)
SELECT colnum1, colnum2, ... FROM table_name WHERE condition;SELECT * FROM customers WHERE country='Mexico';SELECT * FROM customers WHERE customerID=1;SQL에서 텍스트를 입력할 때에는 작은 따옴표가 필요하지만 숫자는 따옴표가 필요하지 않습니다.
연산자를 사용할 수 있습니다.
Equal( = ), Greater than( > ), Less than( < ), Greater than or equal( >= ), Less than or equal( <= ), Not equal( <> )
Between a certain range( BETWEEN ), Search for a pattern( LIKE ), To specify multiple possible values for a column( IN )
SELECT * FROM Products WHERE Price BETWEEN 50 AND 60;SELECT * FROM Customers WHERE City LIKE 's%';SELECT * FROM Customers WHERE City IN ('Paris','London');AND, OR, NOT
WHERE은 AND, OR, NOT과 결합하여 레코드를 필터링 할 수 있습니다.
AND와 OR에는 두개의 조건이 필요합니다. AND는 모든 조건이 참인 레코드, OR는 하나라도 참인 레코드가 표시됩니다.
NOT은 조건이 참이 하닌 레코드를 표시합니다.
AND
SELECT * FROM Customers WHERE Country='Germany' AND City='Berlin';OR
SELECT * FROM Customers WHERE City='Berlin' OR City='München';NOT
SELECT * FROM Customers WHERE NOT Country='Germany';AND, OR, NOT 결합
SELECT * FROM Customers WHERE Country='Germany' AND (City='Berlin' OR City='München');SELECT * FROM Customers WHERE NOT Country='Germany' AND NOT Country='USA';ORDER BY
결과 집합을 오름차순(ASC) 또는 내임차순(DESC)으로 정렬합니다.
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC;SELECT * FROM Customers ORDER BY Country DESC;두가지 열을 기준으로 정렬합니다. country를 기준으로 정렬하지만 동일한 데이터가 있다면 customerName을 기준으로 정렬합니다.
SELECT * FROM Customers ORDER BY Country, CustomerName;country가 오름차순으로 정렬되고, 동일한 데이터가 있다면 customerName을 기준으로 내림차순 정렬됩니다.
SELECT * FROM Customers ORDER BY Country ASC, CustomerName DESC;INSERT INTO
두가지 방법으로 테이블에 새 레코드를 삽입할 수 있습니다.
첫번째 방법은 열 이름과 삽입할 값을 모두 지정합니다.
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);두번째는 테이블의 모든 열에 값을 추가하는 경우로써 열 이름을 지정하지 않습니다.
그러나 값의 순서가 테이블의 열과 동일한 순서인지 확인해야합니다.
INSERT INTO table_name VALUES (value1, value2, value3, ...);삽입되는 데이터의 ID값은 지정하지 않아도 자동으로 생성됩니다. (AUTO INCREMENT Field)
NULL Value
NULL 값을 가진 필드는 값이 없는 필드입니다.
테이블의 필드에 값이 추가되지 않고 새 레코드를 삽입하거나 업데이트하였을때 필드가 NULL값으로 저장됩니다.
NULL값은 0값 또는 공백의 필드와 다릅니다. NULL값을 가진 필드는 작성 중에 비어있는 필드입니다.
NULL Value 확인
비교 연산자로 NULL값을 테스트 할 수 없고, IS NULL, IS NOT NULL 연산자를 사용해야 합니다.
IS NULL
address 필드에 NULL 값을 가진 customers를 나열합니다.
SELECT CustomerName, ContactName, Address FROM Customers WHERE Address IS NULL;IS NOT NULL
address 필드에 NULL 값을 가지지 않은 customers를 나열합니다.
SELECT column_names FROM table_name WHERE column_name IS NOT NULL;UPDATE
테이블의 기존 레코드를 수정합니다.
UPDATE Customers SET ContactName = 'Alfred Schmidt', City= 'Frankfurt' WHERE CustomerID = 1;UPDATE 문에서 WHERE 은 업데이트 할 레코드를 지정합니다. WHERE을 생략하면 테이블의 모든 레코드가 업데이트됩니다.
WHERE이 업데이트 할 레코드 수를 결정합니다.
다음은 해당 country 값을 가진 contactName을 해당 값으로 바꿉니다.
UPDATE Customers SET ContactName='Juan' WHERE Country='Mexico';WHERE이 생략되면 모든 레코드가 업데이트됩니다.
UPDATE Customers SET ContactName='Juan';LIKE
WHERE로 열에서 지정된 패턴을 검색합니다. 와일드카드를 사용합니다.
LIKE Operator Description WHERE CustomerName LIKE 'a%' "a"로 시작하는 값을 찾습니다. WHERE CustomerName LIKE '%a' "a"로 끝나는 값을 찾습니다. WHERE CustomerName LIKE '%or%' "or"이 어느 위치이든 포함하는 값을 찾습니다. WHERE CustomerName LIKE '_r%' "r"이 처음에서 두번째 위치에 있는 값을 찾습니다. WHERE CustomerName LIKE 'a_%' "a" 로 시작하고 최소 2자리인 값을 찾습니다. WHERE CustomerName LIKE 'a__%' "a" 로 시작하고 최소 3자리인 값을 찾습니다. WHERE ContactName LIKE 'a%o' "a" 로 시작하고 "o"로 끝나는 값을 찾습니다. SELECT * FROM Customers WHERE CustomerName NOT LIKE 'a%';Wildcards
와일드 카드 문자는 LIKE 연산자와 함께 사용되어 문자열에서 하나 이상의 문자를 대체하는 데 사용됩니다.
Symbol Description Example % Represents zero or more characters bl% finds bl, black, blue, and blob _ Represents a single character h_t finds hot, hat, and hit [] Represents any single character within the brackets h[oa]t finds hot and hat, but not hit ^ Represents any character not in the brackets h[^oa]t finds hit, but not hot and hat - Represents a range of characters c[a-b]t finds cat and cbt SELECT * FROM Customers WHERE City LIKE '[a-c]%';SELECT * FROM Customers WHERE City LIKE '[!bsp]%';SQL Aliases
테이블이나 테이블의 열의 이름을 임시 이름을 붙여서 읽기 쉽게 만듭니다.
임시로 customerID 열의 이름을 ID로 바꾸고 customerName 열의 이름을 custamer로 바꿉니다.
SELECT CustomerID AS ID, CustomerName AS Customer FROM Customers;Aliases에 공백이 있으면 큰 따옴표나 대괄호가 필요합니다.
SELECT CustomerName AS Customer, ContactName AS [Contact Person] FROM Customers;4개(address, postalCode, city, country)의 열을 결합하고 address라는 이름을 붙여서 한번에 보여줍니다.
SELECT CustomerName, Address + ', ' + PostalCode + ' ' + City + ', ' + Country AS Address FROM Customers;SELECT CustomerName, CONCAT(Address,', ',PostalCode,', ',City,', ',Country) AS Address FROM Customers;두개의 테이블(customers, orders)에서 데이터를 가져올 경우에 유용하게 사용될 수 있습니다.
customers를 'c'로 바꾸고, orders를 'o'로 바꾸어 사용하는 예입니다.
SELECT o.OrderID, o.OrderDate, c.CustomerName FROM Customers AS c, Orders AS o WHERE c.CustomerName='Around the Horn' AND c.CustomerID=o.CustomerID;SQL JOIN
둘 사이의 관련 열을 기반으로 둘 이상의 테이블의 행을 결합하는 데 사용됩니다.
JOIN은 4가지 유형이 있습니다.
(INNER) JOIN : 두 테이블에서 일치하는 값을 가진 레코드를 리턴합니다.
LEFT (OUTER) JOIN : 왼쪽 테이블의 모든 레코드와 오른쪽 테이블의 일치하는 레코드를 반환합니다.
RIGHT (OUTER) JOIN : 오른쪽 테이블의 모든 에코드와 왼쪽 테이블의 일치하는 레코드를 반환합니다.
FULL (OUTER) JOIN : 왼쪽 또는 오른쪽 테이블에 일치하는 모든 레코드를 반환합니다.

INNER JOIN
두 테이블 모두에서 값이 일치하는 레코드를 선택합니다.

SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;orders와 customers를 customerID를 기준으로 JOIN하고 JOIN된 상태에서 orders.orderID와 customers.customerName열을 표시합니다. 만약에 orders 테이블과 customers 테이블에 일치하지 않는 레코드가 있으면 표시되지 않습니다.
SELECT Orders.OrderID, Customers.CustomerName, Shippers.ShipperName FROM ((Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID) INNER JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID);LEFT JOIN
왼쪽 테이블 (table1)의 모든 레코드와 오른쪽 테이블 (table2)의 일치된 레코드를 반환합니다.
오른쪽에서 일치하는 것이 없으면 결과는 오른쪽의 값은 NULL입니다. 왼쪽 테이블은 모든 레코드를 반환합니다.

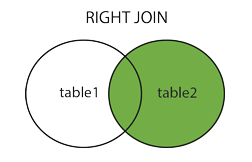
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID ORDER BY Customers.CustomerName;RIGHT JOIN
오른쪽 테이블 (table2)의 모든 레코드와 왼쪽 테이블 (table1)의 일치 된 레코드를 반환합니다.
왼쪽에서 일치하는 것이 없으면 결과는 왼쪽의 값은 NULL입니다. 오른쪽 테이블은 모든 레코드를 반환합니다.
'Today I Learned' 카테고리의 다른 글
TIL_200617 (0) 2020.06.18 TIL_200615 (Sequelize) (0) 2020.06.15 TIL_200601 (0) 2020.06.02 TIL_200531 (Express 공식문서 부수기) (0) 2020.05.31 TIL_200530 (What is Express) (0) 2020.05.31